Abstract
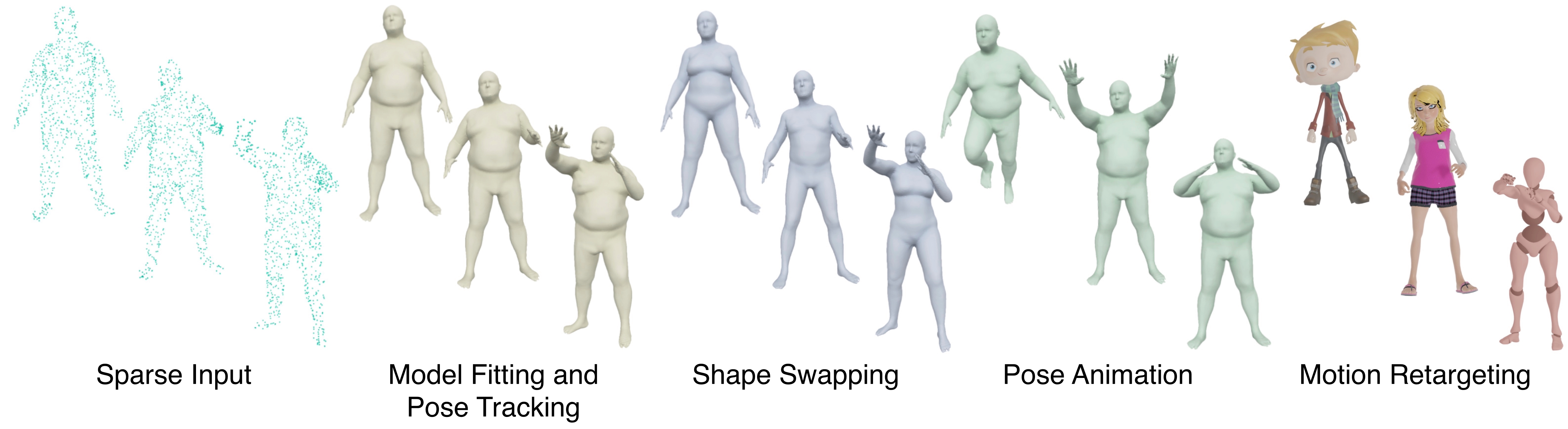
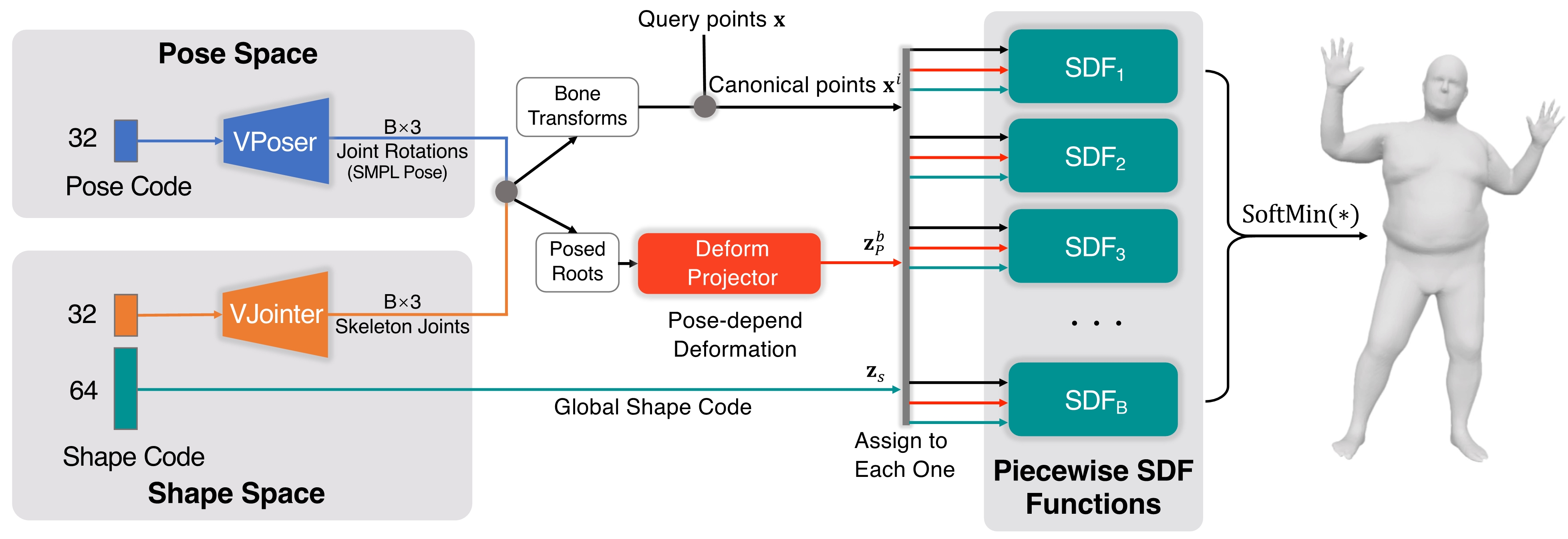
3D representation and reconstruction of human bodies have been studied for a long time in computer vision. Traditional methods rely mostly on parametric statistical linear models, limiting the space of possible bodies to linear combinations. It is only recently that some approaches try to leverage neural implicit representations for human body modeling, and while demonstrating impressive results, they are either limited by representation capability or not physically meaningful and controllable. In this work, we propose a novel neural implicit representation for the human body, which is fully differentiable and optimizable with disentangled shape and pose latent spaces. Contrary to prior work, our representation is designed based on the kinematic model, which makes the representation controllable for tasks like pose animation, while simultaneously allowing the optimization of shape and pose for tasks like 3D fitting and pose tracking. Our model can be trained and fine-tuned directly on non-watertight raw data with well-designed losses. Experiments demonstrate the improved 3D reconstruction performance over SoTA approaches and show the applicability of our method to shape interpolation, model fitting, pose tracking, and motion retargeting.